Redis 基本操作
之前学了数据库,比如MySQL, PostgreSQL,这种全都是关系型数据库,它们都存在显著的问题,那就是按照木桶效应,速度最慢的硬盘成为了提升性能的瓶颈。而Redis等非关系型数据库(NoSQL)则是一种解决方案,它可以将数据存储在内存中,这样就可以提升性能。
基本特点
Redis是一个开源的高性能键值存储数据库(也就是采用Key: Value的键值对形式存储),它支持多种数据结构,包括字符串、哈希、列表、集合、有序集合、位图和 HyperLogLog。Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。Redis支持主从复制,可以实现读写分离,提高系统的可用性。Redis支持事务,可以一次执行多个命令,减少客户端与服务器之间的通信次数,提高性能。
有一个非常重要的,就是Redis是Case-Sensitive的,也就是说,Redis对大小写敏感,所以你不能把一个Key设置成”foo”,然后再设置成”Foo”,否则会导致查询不到数据。
持久化
由于Redis是存储在内存当中的,为了数据的持久化,我们还是需要一种方式存回到硬盘这种持久化存储器当中。Redis提供了两种持久化方式,第一种是RDB持久化,它会将内存中的数据以快照的方式,按照固定的时间间隔(如果修改操作越频繁,则该时间间隔越短)写入磁盘,恢复时会恢复到最近一次快照的状态。第二种是AOF持久化,它会将内存中的数据以日志的形式写入磁盘,恢复时会根据日志中的指令来恢复数据。
还可以通过save命令,手动触发RDB持久化,也可以通过bgsave命令,后台异步执行RDB持久化。
主从复制
Redis支持主从复制,一个主节点(Master)可以对应多个从节点(Slave),主节点会将自己的数据异步地更新到从节点,从节点可以实现读写分离,提高系统的可用性。
哨兵模式
Redis的哨兵模式是一种高可用性的模式,它可以实现Redis的主从复制,并提供监控、通知和自动故障转移等功能。
安装配置就不讲了,提一点Redis只能安装在Linux环境下,Windows环境下只能作为客户端使用。
基本操作
启动
-
启动Redis服务
1 2 3redis-server -
启动Redis命令行客户端
Terminal window
1 2 3 4 5 6 7redis-cli // 连接到Redis服务 redis-cli -h 127.0.0.1 -p 6379 // 连接到指定IP和端口的Redis服务 redis-cli -raw // 显示原始的命令输出,比如你输入一个中文作为值,Redis会显示十六进制,使用-raw参数可以显示中文
基本增删查改
-
增
1 2 3 4 5 6 7SET key value // 设置键值对,其中key会被当成string类型的键,value会被当中值 SETEX key seconds value // 设置键值对,并设置过期时间,单位为秒,过了这个时间后,Redis会自动删除这个键值对 SETNX key value // 设置键值对,如果键不存在,则设置成功,否则do nothing -
删
1 2 3DEL key // 删除键值对 -
查
1 2 3GET key // 获取键值对key对应的值 -
批量操作(在操作之前加个M前缀)
1 2 3 4 5MSET key1 value1 key2 value2 // 批量设置键值对 MGET key1 key2 // 批量获取键值对
列表操作(List)
-
增
1 2 3 4 5LPUSH key value // 在列表key的左侧添加一个值value RPUSH key value // 在列表key的右侧添加一个值value -
删
1 2 3 4 5 6 7 8 9 10 11LPOP key // 从列表key的左侧删除一个值并返回 RPOP key // 从列表key的右侧删除一个值并返回 LPOP key n // 从列表key的左侧删除n个值并返回 RPOP key n // 从列表key的右侧删除n个值并返回 LTRIM key start end // 截取列表key的部分元素,从start开始到end结束 -
查
1 2 3 4 5LRANGE key start end // 获取列表key的start到end之间的元素,总的来说用法类似Python的Slicing LLEN key // 获取列表key的长度
哈希操作(Hash)
Redis的哈希表是String类型的field和value的映射表,它是一种非常灵活的数据结构。你可以理解为一个string对应一个map,field是key,value是value。
-
增
1 2 3 4 5HSET key field value // 设置哈希表key中field对应的值为value HMSET key field1 value1 field2 value2 // 批量设置哈希表key中多个field的值 -
删
1 2 3HDEL key field // 删除哈希表key中field对应的值 -
查
1 2 3 4 5 6 7 8 9 10 11HGET key field // 获取哈希表key中field对应的值 HEXISTS key field // 判断哈希表key中是否存在field对应的值 HGETALL key // 获取哈希表key中所有键值对 HKEYS key // 获取哈希表key中所有键 HVALS key // 获取哈希表key中所有值
集合操作(Set)
-
增/删
1 2 3 4 5SADD key value // 在集合key中添加一个值value SREM key value // 从集合key中删除一个值value -
查
1 2 3 4 5 6 7SMEMBERS key // 获取集合key中的所有元素 SCARD key // 获取集合key的元素个数 SISMEMBER key value // 判断值value是否在集合key中
有序集合操作(Sorted Set)(按照score升序排序)
-
增
1 2 3ZADD key score value // 在有序集合key中添加一个值value,并给这个值设置一个分数score -
删
1 2 3 4 5ZREM key value // 从有序集合key中删除一个值value ZREMRANGEBYSCORE key min max // 从有序集合key中删除分数在min和max之间的元素 -
查
1 2 3 4 5 6 7ZRANGE key start end // 获取有序集合key的start到end之间的元素 ZRANGEBYSCORE key min max // 获取有序集合key中分数在min和max之间的元素 ZCARD key // 获取有序集合key的元素个数
位图操作(Bitmap)
value全为0或1的bitmap,可以用来做一些高效的位运算操作。
-
增
1 2 3 4 5 6 7SETBIT key offset value // 设置位图key的offset偏移量的值为value SET key value // 比如value为"/xF0"其实就直接设置了八位,其中前四位为1,后四位为0 BITFIELD key:fieldname INCRBY u8 field value // 给哈希表key的field对应的值做增量操作,可以对一个字节进行操作 -
删
1 2 3BITOP operation destkey key [key ...] // 对位图key1和key2执行位运算操作,并将结果保存到destkey中 -
查
1 2 3 4 5GETBIT key offset // 获取位图key的offset偏移量的值 BITCOUNT key [start end] // 获取位图key的非零元素个数
事务(Transaction)
Redis事务提供了一种将多个命令操作在一个事务中执行的机制。在关系型数据库种,事务中的命令要么全部执行成功,要么全部执行失败。但是Redis不一样,事务中某条命令失败,不会影响其他命令的执行。
-
开启事务
1 2 3MULTI // 开启事务 -
命令入队
1 2 3 4 5SET key value // 将值value设置到键key APPEND key value // 将值value追加到键key的末尾 -
执行事务
1 2 3EXEC // 执行事务 -
取消事务
1 2 3DISCARD // 取消事务
订阅发布(Pub/Sub)
-
订阅
1 2 3SUBSCRIBE channel1 [channel2 ...] // 订阅一个或多个频道 -
发布
1 2 3PUBLISH channel message // 发布消息到一个频道 -
取消订阅
1 2 3UNSUBSCRIBE [channel ...] // 取消订阅一个或多个频道
Stream操作(Stream)
-
创建
1 2 3XADD stream-key * field value [field value ...] // 创建一个新的Stream -
读
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15XRANGE stream-key start end // 获取Stream中start到end之间的消息 XREVRANGE stream-key end start // 获取Stream中start到end之间的消息,相当于反向查询 XRANGE stream-key - + // 获取Stream中所有的消息 XLEN stream-key // 获取Stream的消息个数 XREAD BLOCK milliseconds STREAMS stream-key [stream-key ...] ID [ID ...] // 读取Stream中的消息,并设置超时时间 XGROUP CREATE stream-key group-name id $ // 创建一个新的消费组 XREADGROUP GROUP group-name consumer-name BLOCK milliseconds STREAMS stream-key [stream-key ...] ID [ID ...] // 读取Stream中的消息,并设置超时时间 -
删
1 2 3XDEL stream-key ID [ID ...] // 删除Stream中的消息
HyperLogLog操作(HyperLogLog)
有点像布隆过滤器,有效率和内存的优势,但是需要牺牲一定的准确性。
-
增
1 2 3PFADD key element [element ...] // 添加元素到HyperLogLog中 -
删
1 2 3PFCOUNT key [key ...] // 获取HyperLogLog中元素的个数 -
查
1 2 3PFMERGE destkey sourcekey [sourcekey ...] // 将多个HyperLogLog合并到一个HyperLogLog中
Redis 整合
还是再提一下常考的RDB和AOF,二者都是为了保证数据的持久化,比较Redis是存在内存当中的,还是不可避免的要保存到硬盘中。
RDB: 以快照的方式,以一定的时间间隔存到硬盘当中,这个间隔会因为存储频率的变化而变化。
AOF: 以日志的方式,记录对数据库执行的所有操作,只要操作成功,就会被追加到文件末尾。
引入依赖
在Spring Boot中集成Redis,需要在pom.xml中添加Redis的依赖:
|
|
配置application.yml
然后在application.yml中配置Redis的连接信息:
|
|
注入
然后就可以在Spring Boot的Bean中注入RedisTemplate,进行Redis的操作:
|
|
或者注入StringRedisTemplate,进行字符串操作:
|
|
这样就可以在Spring Boot中使用Redis了。
基本用法
-
String:
-
set
1 2 3stringRedisTemplate.opsForValue().set(key, value); -
get
1 2 3stringRedisTemplate.opsForValue().get(key); -
delete
1 2 3stringRedisTemplate.delete(key); -
expire
1 2 3stringRedisTemplate.expire(key, timeout, timeUnit); -
exists
1 2 3stringRedisTemplate.hasKey(key);
-
-
Hash
-
put
1 2 3stringRedisTemplate.opsForHash().put(key, hashKey, value); -
putAll
一次性把所有field-value对存入hashmap中1 2 3 4 5 6 7 8 9Map<String, String> map = new HashMap<>(); map.put("key1", "value1"); map.put("key2", "value2"); stringRedisTemplate.opsForHash().putAll(key, map); -
get
1 2 3stringRedisTemplate.opsForHash().get(key, hashKey); -
expire
1 2 3stringRedisTemplate.expire(key, timeout, timeUnit); -
delete
1 2 3stringRedisTemplate.opsForHash().delete(key, hashKey);也可以一次把key对应的所有field-value对删除
1 2 3stringRedisTemplate.delete(key);
-
-
List
-
leftPush
1 2 3stringRedisTemplate.opsForList().leftPush(key, value); -
rightPush
1 2 3stringRedisTemplate.opsForList().rightPush(key, value); -
leftPop
1 2 3stringRedisTemplate.opsForList().leftPop(key); -
rightPop
1 2 3stringRedisTemplate.opsForList().rightPop(key); -
size
1 2 3stringRedisTemplate.opsForList().size(key); -
range
1 2 3stringRedisTemplate.opsForList().range(key, start, end); -
expire
1 2 3stringRedisTemplate.expire(key, timeout, timeUnit); -
delete
1 2 3stringRedisTemplate.opsForList().delete(key, index);
-
-
Set
-
add
1 2 3stringRedisTemplate.opsForSet().add(key, value); -
size
1 2 3stringRedisTemplate.opsForSet().size(key); -
members
1 2 3stringRedisTemplate.opsForSet().members(key); -
expire
1 2 3stringRedisTemplate.expire(key, timeout, timeUnit); -
delete
1 2 3stringRedisTemplate.opsForSet().delete(key, value);
-
其他的暂且不提,因为用的确实比较少
问题记录
接下来记录一下我遇到的问题
-
在我们使用
@Autowired注解尝试对redisTemplate进行注入时会报Warning。这个呢,你要么用
@Resource注解,要么用IDEA推荐的方法,将要注入的redisTemplate通过输入的参数来获取 -
StringRedisTemplate能用,但是RedisTemplate使用报null的错。这个是因为两者默认的序列化方式不同,你注意发现的话,前者在redis中显示的方式就是可阅读的字符串,而后者则是
0x开头的字节码形式。所以如果你要用RedisTemplate,需要我们去配置一下redisTemplate的序列化方式。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31// 这个可以放在config包下的RedisConfig类中 // 这里的Object可以替换成你要序列化的对象类型 @Configuration public class RedisConfig { @Bean public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) { RedisTemplate<String, Object> template = new RedisTemplate<>(); template.setConnectionFactory(factory); template.setKeySerializer(new StringRedisSerializer()); template.setValueSerializer(new GenericJackson2JsonRedisSerializer()); template.setHashKeySerializer(new StringRedisSerializer()); template.setHashValueSerializer(new GenericJackson2JsonRedisSerializer()); return template; } }
JWT+Redis实现登录认证
为什么采用这个组合实现登录认证
JWT (JSON Web Token) 在 Spring Boot 中非常流行,也是比较推荐的一种登录认证方式。它具有以下优点:
- 安全性: JWT 使用签名和加密技术,可以有效地防止数据篡改和伪造。
- 无状态性: JWT 不需要服务器维护用户的登录状态,简化了服务器端的实现,并提高了可扩展性。
- 跨平台性: JWT 可以在不同的平台和系统之间传递,方便跨平台应用。
另外在分布式系统当中,对于每个服务器都同时更新token也是不现实的,这样反而加大了服务器的压力。所以我们可以采用 Redis 来存储 JWT,这样每个服务器只需要更新 Redis 中的 token 即可,其他服务器可以从 Redis 中获取到最新有效的 token 进行验证。大概的结构就是客户端->Redis->多台服务器。
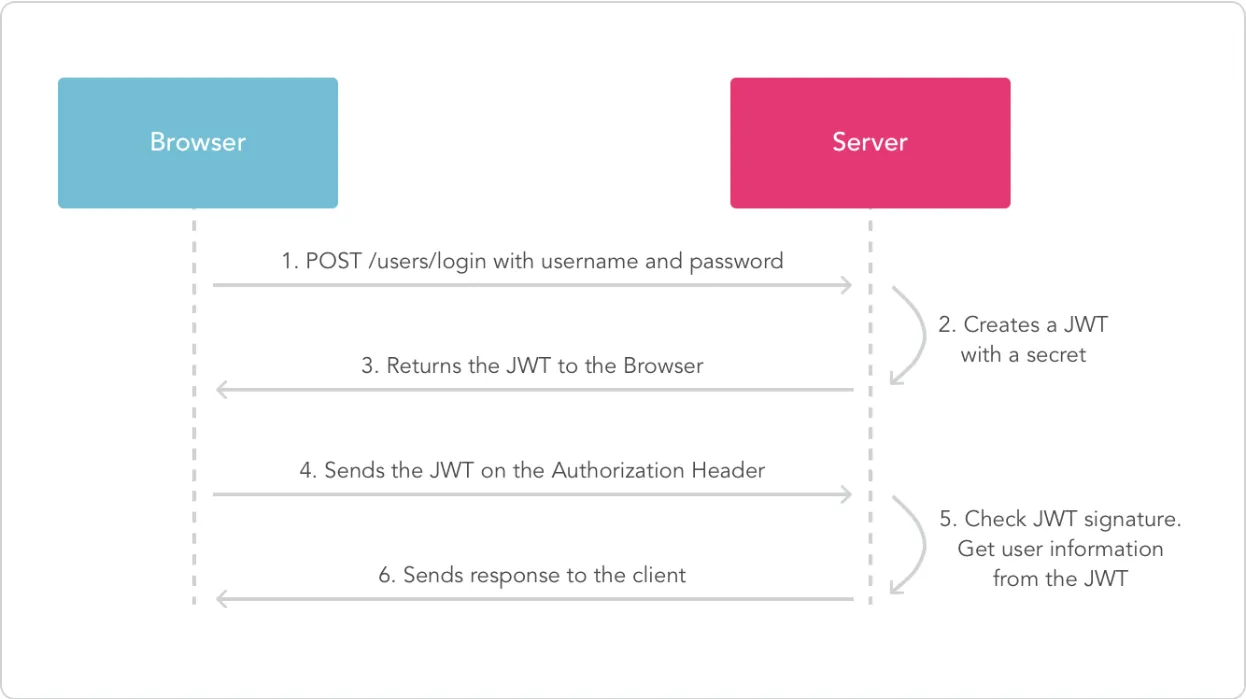
大概流程
使用 JWT 和 Redis 实现登录认证的流程通常如下:
- 用户登录: 用户提交用户名和密码,服务器进行验证。
- 生成 JWT: 如果验证通过,服务器生成一个 JWT,包含用户基本信息、权限等。
- 存入 Redis: 将生成的 JWT 以及相关信息存储到 Redis 中,例如:
- 键: 用户 ID 或用户名。
- 值: JWT 以及过期时间。
- 返回 JWT: 服务器将 JWT 返回给客户端。
- 客户端使用 JWT: 客户端后续请求时,将 JWT 添加到请求头中。
- 服务器验证 JWT: 服务器从 Redis 中获取该用户的 JWT,验证其有效性。
- 授权: 如果 JWT 验证通过且未过期,则允许访问资源,否则拒绝访问。
访问的过程大概如下(图片来自这篇文章)
代码实现
引入依赖
这里只显示本文重点的两个依赖,其他依赖的话,比如jjwt-api这种就不显示了。
此外也可以换用其他的,比如jjwt的0.12.x版本,或者auth0的java-jwt。
|
|
配置 Redis
这个也是Redis专栏提到过的,可个性化配置
|
|
实现登录认证
只是举个例子,不保证适用性
创建一个JWTUtils工具类,用于生成和验证JWT
|
|
实现登录逻辑,即Controller
|
|
实现拦截器,防止未登录用户访问受保护资源
|
|
Redis 缓存
缓存基础和主动更新
基础模板
一般基础使用都是这个模板
|
|
主动更新策略
然而基础模板效率来说其实是不高的,因为在于它的逐出策略,是到了时间才将其删除,那假设一种情况,每一个缓存进来之后,都没再被用过了,都是等到expire时间到了才消失,这样的话这个缓存设置就没意义了。
解决方案就是用主动更新策略,主动地去删除无用缓存,同时为了保证缓存一致性和缓存与数据库的资源一致,我们先操作数据库,然后再删除缓存。
-
对于低一致性要求确实可以用超时自动删除,但是对于高一致性要求,我们还是需要主动更新。
-
对于读操作还是不变的,先读缓存,读到就返回,没有的话再读数据库,然后更新缓存。
-
对于写操作,先更新数据库,然后删除缓存。
|
|
缓存进阶和实际问题
常见的几个问题
-
缓存穿透问题:缓存和数据库都没有,每次查询都要去数据库,这样会导致数据库压力过大,造成系统崩溃。
- 在第一次到缓存未命中到达数据库后,发现符合缓存穿透条件,设置一个空值缓存(有过期时间),当查询不到数据时,直接返回空值。
- 布隆过滤器: 这样的话结构本来是发出查询->redis缓存->数据库,要在查询和缓存间加一层BloomFilter。如果检测到查询的key不存在于数据库中,则直接报错;如果在数据库中,则更布隆过滤器。
-
缓存雪崩问题:缓存服务器宕机或同一时段大量缓存失效,导致大量请求直接落到数据库,数据库压力过大,造成系统崩溃。
- 随机设置缓存过期时间,避免缓存雪崩。
- Redis集群: 避免缓存雪崩,可以将缓存分布到多个Redis节点上,避免单点故障。
- 降级限流: 直接限制对服务器的查询请求,返回错误,不对数据库产生进一步的压力。
- 添加多级缓存
-
缓存击穿问题:缓存击穿是指对于某个被高并发且缓存构建业务比较复杂的key,缓存中没有,但是数据库中有,每次查询都要去数据库,造成数据库压力过大,造成系统崩溃。
- 互斥锁: 对于查询某个key的请求,当缓存没有命中时,加互斥锁,查询数据库返回请求,并在缓存中设置这个key,再释放锁,避免其他线程在查询重建时期的多次访问。
- 逻辑过期: 对于那些已经判断为热点高并发的资源,直接把它定死在redis当中,保证热点资源每时每刻都在缓存中,虽然可能会有旧的没更新的。对于过期时间,直接以值的形式存到redis的value一栏当中,这样即使到了过期时间它也不会被redis删除。如果过期了,则开另外一个线程去查询数据库,更新缓存。
Redis如何上锁
我们可以使用Redis的setnx命令来实现分布式锁,setnx命令的作用是设置一个key,当key不存在时,才会设置成功,如果key已经存在,则不设置成功。
(为什么我们需要用Redis实现分布式锁?因为Java当中的比如synchronized的锁,在分布式环境下是不安全的,因为它只能锁住一个线程,而分布式环境下,线程是分布在不同的机器上的,只有使用Redis的锁来统一进行控制,才能保证线程间的互斥。)
这样可以发现,setnx的性质很好刚好就契合了锁的功能。因为如果key不存在,则说明没有人持有锁,可以加锁,如果key已经存在,说明有人持有锁,再怎么申请都不能加锁。
但是还是要注意,如果一个持有锁的程序崩溃了,锁就会一直存在,造成死锁。所以我们还需要类似RAII思想,设置一个过期时间,避免锁一直存在。
|
|
逻辑过期
|
|
高阶改进
上面的实现看起来还是非常朴素的,还有非常多的优化空间
封装整个Redis的工具类
这里就是把上面的代码都复制粘贴到一个独立的类当中,但是注意泛型的使用,要保证泛用性。
使用官方锁
我们自己写的锁,肯定不如它官方锁来的安全,并发度高,支持并发。
比如说,可以使用Redisson来实现分布式锁,它可以自动续期,避免死锁,还可以实现公平锁,避免锁的饥饿。
|
|
使用Redis集群
Redis集群可以提高Redis的读写性能,避免单点故障。
|
|
使用Lua脚本
为什么要使用 Lua 脚本,而不是直接封装 Java 方法,这里我详细为你解释:
- Lua 脚本在 Redis 中的优势:
- 原子性: Lua 脚本在 Redis 中执行是原子性的,保证脚本中的所有操作要么全部执行成功,要么全部执行失败,避免了因并发问题导致数据不一致的情况。在秒杀场景中,原子性保证了库存更新和订单创建的同步,防止超卖问题。
- 效率: Lua 脚本在 Redis 内执行,直接利用 Redis 的内存数据结构进行操作,效率非常高,而 Java 方法则需要进行网络通信,效率相对较低。对于高并发秒杀场景,效率的提升非常关键。
- 安全性: Lua 脚本只能在 Redis 中执行,无法直接访问系统资源,安全性更高,避免了恶意代码执行的风险。
- 为什么不用直接封装 Java 方法?
- 线程安全性: Java 方法在多线程环境中执行需要考虑线程安全问题,需要额外编写代码来保证数据一致性,相对复杂。
- 网络通信: Java 方法需要通过网络通信与 Redis 交互,增加网络延迟,效率降低。
- 数据一致性: 如果 Java 方法执行期间出现异常,可能会导致数据不一致,例如库存更新成功,但订单创建失败。
所以综上所述,lua脚本其实是不能不学的,就算是实际上机开发也是会用到的。
JWT 用户登录系统实现
首先,还是提一下session和token的概念。分别对应有状态和无状态的登录,最大的区别就在于服务器的无状态就是服务器端不保存任何客户端请求者信息,每一次请求都需要客户端自述自证其身份。那么这里聊聊使用token的无状态登录。
登录原理
不论哪种登录模式,其实认证这一关我们都需要做两步
- 告诉系统你是谁
- 让系统确认你就是你
第一点就是我们常输入的账号、手机号、邮箱这种,第二点就是我们通过密码或者手机验证码进行身份的验证。还有就是我们的验证码,比如各种人机测验啊,滑动验证码啊,看图写字母啊,大多数都是为了防止恶意的登录,其实用意并不在身份验证的。
登录流程
其登录流程也比较简单直观:
- 客户端首次登录,服务端进行用户信息认证和校验
- 认证通过,服务器生成token并返回给客户端,token一般包含用户信息,有效期等信息
- 用户token会被保存在redis中,用来验证用户身份
- 客户端每次请求都携带token
- 服务端通过Authorization头部获取token,解密并验证token的有效性,返回数据
再来聊聊注册的逻辑:
- 客户端发送注册请求,服务端校验数据是否合法合理
- 服务器保存用户信息,包括用户名,加密后的密码,头像,创建日期,是否被删除,是否为管理员等
二维码登录
说完了传统登录,再聊聊二维码登录这种形式。二维码其实能存储的内容不多几KB,所以一般用来存一个URL。
一般在这种情况下,我们有三个设备:待登录设备(a),已经登录的扫码设备(b),服务器(c)。
- a向c发送请求生成二维码
- c生成二维码id,并将二维码id和过期时间(二维码一般有有效期)等信息保存到redis中,这个二维码id会根据请求方等因素来保证唯一性
- a根据二维码id生成二维码,并渲染到页面
- b扫描二维码,解析出二维码id
- b使用二维码id和本地token(用来标识登录状态和用户身份)向c请求登录
- c根据二维码id和本地token进行验证,如果验证通过,则向b返回a的信息,以供b确认登录身份
- b确认成功,确定比如是本人操作。同时a进行轮询,显示“待确认”
- c收到b的确认信息,返回登录成功的token给b,并将token保存到redis中
- b将token保存到本地,并在下次请求时携带,以验证身份
Q&A
-
如何获取用户请求携带的token?如何解析token?如何根据token的合法性判别用户的登录状态?
-
通过请求头中获取Authorization字段,然后解析token。解析token的过程可以用jwt工具类来实现。
1 2 3 4 5 6 7public Result getTokens(@RequestHeader("Authorization") String token) { // 这样就可以通过参数的形式操作token了 } -
使用拦截器判断用户是否登录,并从token中获取用户信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77@Component public class LoginInterceptor implements HandlerInterceptor { @Resource private JWTUtil jwtUtil; @Resource private RedisUtil redisUtil; @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { if (!(handler instanceof HandlerMethod)) { return true; } HandlerMethod handlerMethod = (HandlerMethod) handler; RequireLogin requireLogin = handlerMethod.getMethodAnnotation(RequireLogin.class); if (requireLogin == null) { requireLogin = handlerMethod.getBeanType().getAnnotation(RequireLogin.class); } if (requireLogin == null) { return true; // 不需要登录验证 } String token = request.getHeader("Authorization"); if (StrUtil.isBlankIfStr(token)) { response.sendRedirect("/login"); return false; } JWTUtil.TokenValidationResult result = jwtUtil.validateToken(token); if (!result.isValid()) { response.sendRedirect("/login"); return false; } String username = jwtUtil.parseToken(token).getStr("username"); Object storedToken = redisUtil.get(Constants.REDIS_LOGIN_TOKEN_PREFIX + username); if (storedToken == null || !token.equals(storedToken.toString())) { response.sendRedirect("/login"); return false; } return true; } }
-
-
jwt工具类怎么写?
首先我们需要知道,基本三个接口就够用了,生成token,验证token,以及解析token(获取token中的信息)。我们可以自己用jwt库实现,也可以用hutool的工具类。
-
如何防止未登录用户访问受保护的资源?登录后如何跳转页面?
这个问题就是重定向,我们可以加一个登录拦截器,用来拦截用户未登录的请求,并重定向到登录页面;在登录成功后,跳转到某个页面。详见问题1的解答代码。